Maru#
Warning
This page documents the behavior of LMCache’s in-process mode (deprecated). Please consider using LMCache MP mode for better feature support and performance. For the MP mode equivalent of this page, see Secondary KV Storage.
Overview#
Maru is a high-performance KV cache storage engine built on CXL shared memory, designed for LLM inference scenarios where multiple instances need to share a KV cache with minimal latency.
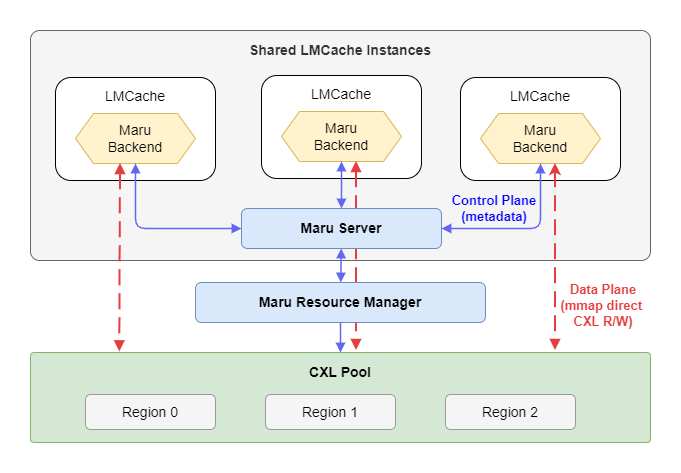
For architecture details, see the Maru documentation.
Quick Start#
Install Maru:
git clone https://github.com/xcena-dev/maru.git
cd maru
./install.sh
This installs maru-server, maru-resourced, and the maru Python package.
Deploy Model With Maru#
Prerequisites: CXL device (/dev/dax*), Python 3.12+, vLLM and LMCache installed.
1. Start the Maru Server
maru-server
2. Create configuration file (maru-config.yaml):
chunk_size: 256
local_cpu: False
max_local_cpu_size: 0
save_unfull_chunk: True
# Maru backend
maru_path: "maru://localhost:5555"
maru_pool_size: 4
3. Start vLLM with Maru
LMCACHE_CONFIG_FILE="maru-config.yaml" \
vllm serve \
meta-llama/Llama-3.1-8B-Instruct \
--max-model-len 65536 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
Configuration#
LMCache Parameters:
Parameter |
Default |
Description |
|---|---|---|
|
Required |
Maru server URL (format: |
|
|
CXL memory pool size per instance in GB (e.g., |
Advanced Parameters (via extra_config):
Parameter |
Default |
Description |
|---|---|---|
|
auto UUID |
Unique client instance identifier |
|
5000 |
ZMQ RPC socket timeout in milliseconds |
|
true |
Async DEALER-ROUTER RPC ( |
|
64 |
Max concurrent async RPC requests |
|
true |
Pre-map all shared regions on connect |