Mooncake#
Warning
This page documents the behavior of LMCache’s in-process mode (deprecated). Please consider using LMCache MP mode for better feature support and performance. For the MP mode equivalent of this page, see Mooncake Store.
Overview#
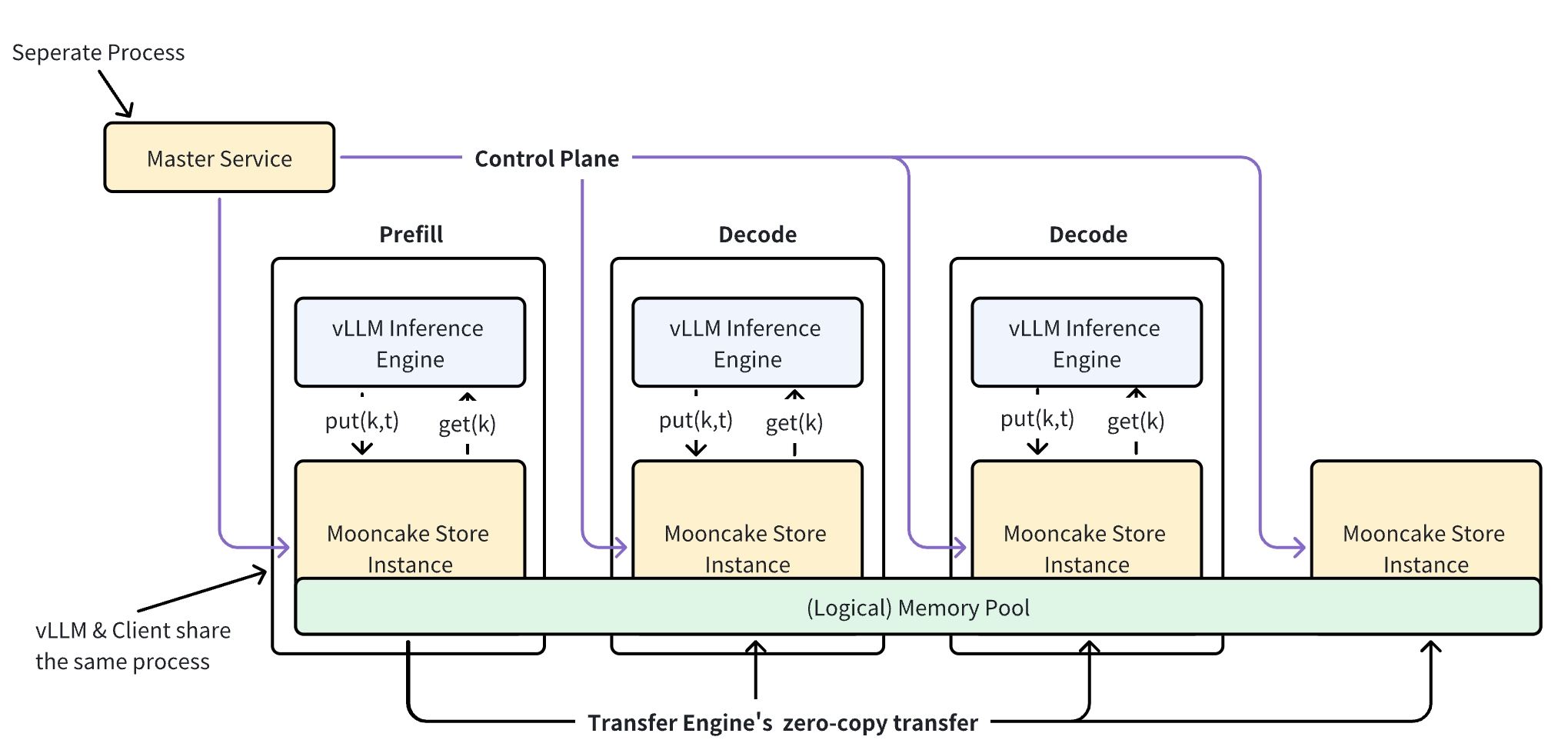
Mooncake is an open-source distributed KV cache storage system designed specifically for LLM inference scenarios. The system creates a distributed memory pool by aggregating memory space contributed by various client nodes, enabling efficient resource utilization across clusters.
By pooling underutilized DRAM and SSD resources from multiple nodes, the system forms a unified distributed storage service that maximizes resource efficiency.
Key Features#
Distributed memory pooling: Aggregates memory contributions from multiple client nodes into a unified storage pool
High bandwidth utilization: Supports striping and parallel I/O transfer of large objects, fully utilizing multi-NIC aggregated bandwidth
RDMA optimization: Built on Transfer Engine with support for TCP, RDMA (InfiniBand/RoCEv2/eRDMA/NVIDIA GPUDirect)
Dynamic resource scaling: Supports dynamically adding and removing nodes for elastic resource management
For detailed architecture information, see the Mooncake Architecture Guide.
Quick Start#
Install Mooncake via pip:
pip install mooncake-transfer-engine
This package includes all necessary components:
mooncake_master: Master service that manages cluster metadata and coordinates distributed storage operationsmooncake_http_metadata_server: HTTP-based metadata server used by the underlying transfer engine for connection establishmentMooncake Python bindings
For production deployments or custom builds, see the Build Instructions.
Setup and Deployment#
Prerequisites:
Machine with at least one GPU for vLLM inference
RDMA-capable network hardware and drivers (recommended) or TCP network
Python 3.8+ with pip
vLLM and LMCache installed
Step 1: Start Infrastructure Services
Start the Mooncake master service (with built‑in HTTP metadata server):
# Master service (use -v=1 for verbose logging)
# The flag enables the integrated HTTP metadata server
mooncake_master --enable_http_metadata_server=1
Expected output:
Master service started on port 50051
HTTP metrics server started on port 9003
Master Metrics: Storage: 0.00 B / 0.00 B | Keys: 0 | ...
Step 2: Create Configuration File
Create your mooncake-config.yaml:
# LMCache Configuration
local_cpu: False
remote_url: "mooncakestore://localhost:50051/"
max_local_cpu_size: 2 # small local buffer
numa_mode: "auto" # reduce tail latency with multi-NUMA/multi-NIC
pre_caching_hash_algorithm: sha256_cbor_64bit
# Mooncake Configuration (via extra_config)
extra_config:
use_exists_sync: true
save_chunk_meta: False # Enable chunk metadata optimization
local_hostname: "localhost"
metadata_server: "http://localhost:8080/metadata"
protocol: "rdma"
device_name: "" # leave empty; autodetect device(s)
global_segment_size: 21474836480 # 20 GiB per worker
master_server_address: "localhost:50051"
local_buffer_size: 0 # rely on LMCache local_cpu as the buffer
mooncake_prefer_local_alloc: true # prefer local segment if available
Step 3: Start vLLM with Mooncake
# If you see persistent misses (no Mooncake hits), make sure
# PYTHONHASHSEED is fixed across processes (e.g., export PYTHONHASHSEED=0).
LMCACHE_CONFIG_FILE="mooncake-config.yaml" \
vllm serve \
meta-llama/Llama-3.1-8B-Instruct \
--max-model-len 65536 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
Step 4: Verify the Setup
Test the integration with a sample request:
curl -X POST "http://localhost:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3.1-8B-Instruct",
"prompt": "The future of AI is",
"max_tokens": 100,
"temperature": 0.7
}'
Debugging Tips:
Enable verbose logging:
mooncake_master -v=1Check service status:
# Check if services are running ps aux | grep mooncake netstat -tlnp | grep -E "(8080|50051)"Monitor metrics:
Access metrics at
http://localhost:9003when master service is running.
Configuration#
LMCache Parameters:
Parameter |
Default |
Description |
|---|---|---|
|
256 |
Number of tokens per KV chunk |
|
Required |
Mooncake store connection URL (format: |
|
“naive” |
Serialization method for remote storage |
|
False |
Enable/disable local CPU caching (set to False for pure Mooncake evaluation) |
|
Required |
Maximum local CPU cache size in GB (required even when local_cpu is False) |
|
“auto” |
NUMA binding mode. “auto” is recommended on multi‑NIC/multi‑NUMA systems to reduce tail latency. |
|
“sha256_cbor_64bit” |
Hash used for pre-caching keying. For cross‑process consistency, fix |
Mooncake Parameters (via extra_config):
Parameter |
Default |
Description |
|---|---|---|
|
Required |
Hostname/IP of the local node for Mooncake client identification |
|
Required |
HTTP metadata server address. When starting master with |
|
Required |
Mooncake master service address (host:port format) |
|
“rdma” |
Communication protocol (“rdma” for high performance; “tcp” for compatibility) |
|
“” |
RDMA device specification (e.g., “erdma_0,erdma_1” or “mlx5_0,mlx5_1”). Leave empty for autodetection in most setups. |
|
21474836480 |
Memory size contributed by each vLLM worker in bytes (e.g., 20 GiB recommended) |
|
0 |
Local buffer size in bytes used by Mooncake. Behavior depends on |
|
1 |
Timeout for transfer operations in seconds |
|
“” |
The root directory for persistence (e.g., “/mnt/mooncake”) |
|
False |
Whether to save chunk metadata alongside data. Set to |
|
False |
Use synchronous existence checks to avoid async scheduling overhead in hot paths. |
|
False |
Prefer allocating on the local segment when possible. |
Important
Understanding global_segment_size: This parameter defines the amount of memory each vLLM worker contributes to the distributed memory pool.
The total cluster memory available for KV cache storage will be: number_of_vllm_workers × global_segment_size.
Adjust this value based on your available system memory and expected cache requirements.
Tip
If you consistently get misses (no Mooncake hits), ensure all processes use the same hashing seed: export PYTHONHASHSEED=0. This keeps pre‑caching keys consistent across processes.
Note
RDMA device(s) usually do not need to be specified; leaving device_name empty works for most deployments.