InfiniStore#
Warning
This page documents the behavior of LMCache’s in-process mode (deprecated). Please consider using LMCache MP mode for better feature support and performance. For the MP mode equivalent of this page, see Secondary KV Storage.
Overview#
InfiniStore is an open-source high-performance KV store. It’s designed to support LLM Inference clusters, whether the cluster is in prefill-decoding disaggregation mode or not. InfiniStore provides high-performance and low-latency KV cache transfer and KV cache reuse among inference nodes in the cluster.
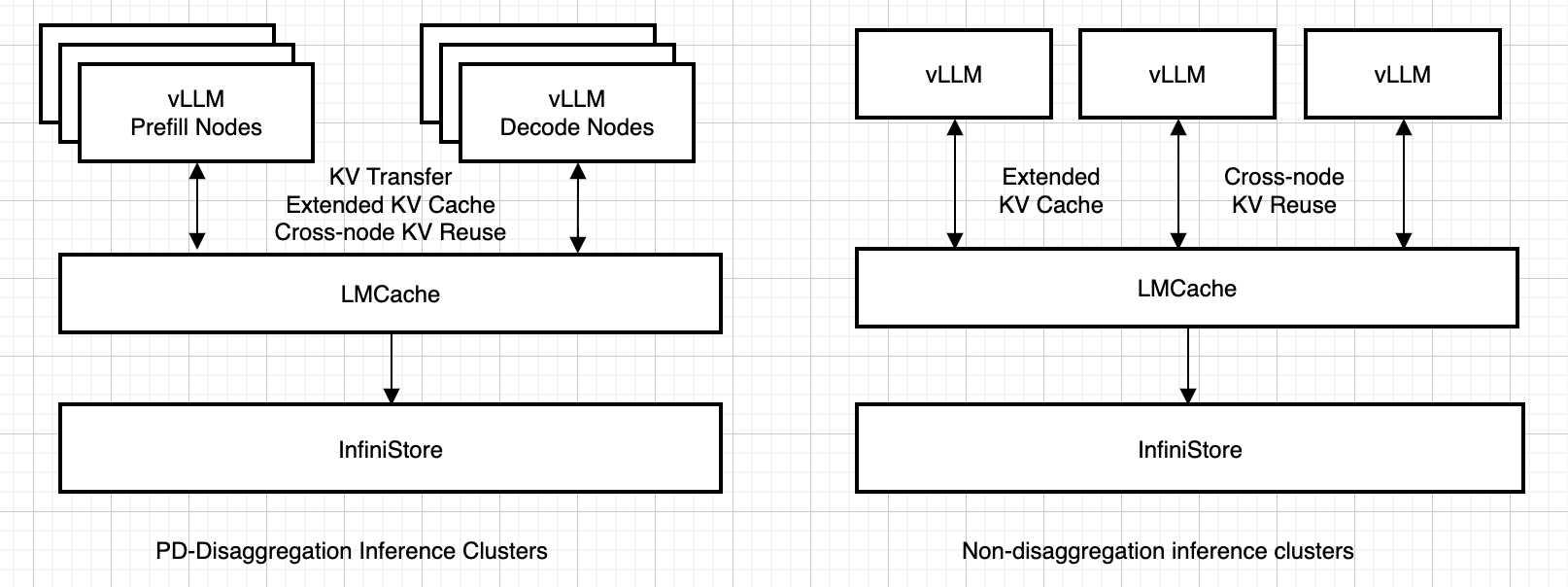
There are two major scenarios how InfiniStore supports:
Prefill-Decoding disaggregation clusters: in such mode inference workloads are separated into two node pools: prefill nodes and decoding nodes. InfiniStore enables KV cache transfer among these two types of nodes, and also KV cache reuse.
Non-disaggregated clusters: in such mode prefill and decoding workloads are mixed on every node. InfiniStore serves as an extra large KV cache pool in addition to GPU cache and local CPU cache, and also enables cross-node KV cache reuse.
For more details, please refer to the InfiniStore Documentation.
InfiniStore supports both RDMA and TCP for transport. LMCache’s InfiniStore connector only uses the RDMA transport.
Quick Start#
Install InfiniStore via pip:
pip install infinistore
This package includes the InfiniStore server and the Python bindings.
To build InfiniStore from source, follow the instructions in the GitHub repository.
Setup and Deployment#
Prerequisites:
Machine with at least one GPU for vLLM inference
RDMA-capable network hardware and drivers
Python 3.8+ with pip
vLLM and LMCache installed
Step 1: Start InfiniStore Server
For InfiniBand based RDMA:
infinistore --service-port 12345 --dev-name mlx5_0 --link-type IB
For RoCE based RDMA:
infinistore --service-port 12345 --dev-name mlx5_0 --link-type Ethernet
You can also specify the --hint-gid-index option to set the GID index for the InfiniStore server. This is useful when you are in a k8s managed environment.
Step 2: Create Configuration File
Create your infinistore-config.yaml:
chunk_size: 256
remote_url: "infinistore://127.0.0.1:12345/?device=mlx5_1"
remote_serde: "naive"
local_cpu: False
max_local_cpu_size: 5
Step 3: Start vLLM with InfiniStore
LMCACHE_CONFIG_FILE="infinistore-config.yaml" \
vllm serve \
Qwen/Qwen2.5-7B-Instruct \
--seed 42 \
--max-model-len 16384 \
--gpu-memory-utilization 0.8 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
Step 4: Verify the Setup
Test the integration with a sample request:
curl -X POST "http://localhost:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"prompt": "The future of AI is",
"max_tokens": 100,
"temperature": 0.7
}'
Debugging Tips:
Enable verbose logging:
infinistore --log-level=debugCheck server status:
# Check if the server is running ps aux | grep infinistore netstat -tlnp | grep -E "12345"
Query TTFT Improvement#
Once the OpenAI compatible server is running, let’s query it twice and see the TTFT improvement.
Run vLLM’s serving benchmark twice with the following parameters:
vllm bench serve \
--backend vllm \
--model Qwen/Qwen2.5-7B-Instruct \
--num-prompts 50 \
--port 8000 \
--host 127.0.0.1 \
--dataset-name random \
--random-input-len 8192 \
--random-output-len 128 \
--seed 42
Example Output:
For the first run, you might see:
============ Serving Benchmark Result ============
Successful requests: 50
Benchmark duration (s): 80.97
Total input tokens: 409544
Total generated tokens: 6273
Request throughput (req/s): 0.62
Output token throughput (tok/s): 77.48
Total Token throughput (tok/s): 5135.74
---------------Time to First Token----------------
Mean TTFT (ms): 36203.54
Median TTFT (ms): 34598.91
P99 TTFT (ms): 76010.91
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 290.30
Median TPOT (ms): 346.25
P99 TPOT (ms): 412.24
---------------Inter-token Latency----------------
Mean ITL (ms): 290.30
Median ITL (ms): 386.78
P99 ITL (ms): 449.83
For the second run, you should see a significant reduction in TTFT:
============ Serving Benchmark Result ============
Successful requests: 50
Benchmark duration (s): 15.14
Total input tokens: 409544
Total generated tokens: 6273
Request throughput (req/s): 3.30
Output token throughput (tok/s): 414.22
Total Token throughput (tok/s): 27457.55
---------------Time to First Token----------------
Mean TTFT (ms): 2880.53
Median TTFT (ms): 3118.50
P99 TTFT (ms): 12027.24
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 73.81
Median TPOT (ms): 71.12
P99 TPOT (ms): 91.24
---------------Inter-token Latency----------------
Mean ITL (ms): 73.81
Median ITL (ms): 63.86
P99 ITL (ms): 565.44
TTFT Improvement: 33.323 seconds (12.6x faster).
Tips:
If you want to run vLLM’s serving benchmark multiple times, you’ll need to either restart the vLLM LMCache server and the InfiniStore server, or change the
--seedparameter to a different value each time, since you’ve already warmed up LMCache.The benchmark result here was produced by running an L40 with 48GB of GPU memory with
--gpu-memory-utilization 0.8. You can adjust the GPU memory utilization and increase the max model length to use more of the long context. LMCache TTFT improvement becomes more pronounced as the context length increases!