Welcome to LMCache!#
A KV Cache Management Layer for Scalable LLM Inference.
Note
We are currently in the process of upgrading our documentation to provide better guidance and examples. Some sections may be under construction. Thank you for your patience!
LMCache is a KV cache management layer for LLM inference. It turns KV cache from a temporary state into reusable AI-native knowledge that can be stored persistently, reused across multiple serving engines, monitored with an observability stack, and transformed for better generation quality. As a result, LMCache reduces TTFT (time-to-first-token) and improves throughput, especially for long-context agentic, multi-turn conversation, and knowledge-augmented workloads (e.g., RAG).
LMCache is vendor-neutral. It can be used as a KV cache layer for a range of mainstream open-source serving engines, inference frameworks, hardware vendors, storage systems, and infrastructure providers. The vendor neutrality allows users to freely switch between serving engines and storage vendors, while reusing the stored KV caches.
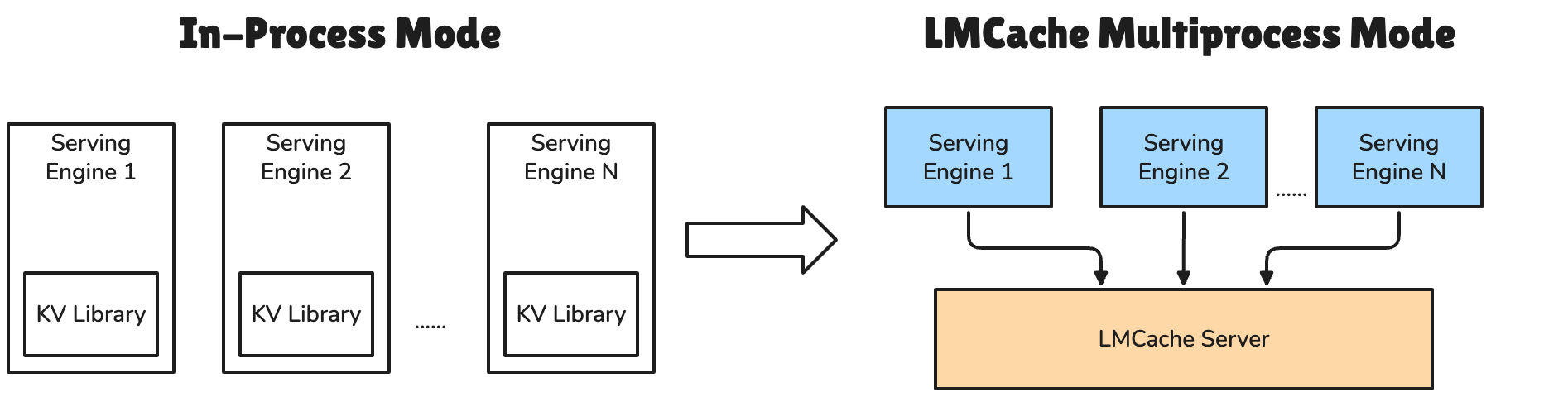
Key features#
Engine-independent deployment: LMCache, as a standalone daemon process, manages KV cache independently from the inference engine process, so that KV cache will not be lost even if the inference engine crashes (i.e., no fate-sharing with engines).
Persistent, tiered KV cache offloading and reuse: Move KV caches out of GPU memory into a tiered storage hierarchy spanning CPU memory, local storage, and remote backends, enabling reuse across requests, sessions, and engine instances to reduce repeated prefill computation and improve TTFT.
Production-level KV cache observability: LMCache provides a rich set of KV cache observability metrics, including typical Kubernetes metrics (health monitoring, performance diagnostics), KV-cache-specific metrics (request-level and token-level prefix cache hits, lifecycle, request-level KV cache performance), management metrics (user-specific usage), and more.
Pluggable storage and transport backends: Easily integrate remote storage and KV transfer backends through a unified interface, enabling KV cache offloading and sharing across storage providers. Through this interface, LMCache supports storage backends including CPU RAM, local disk (SSD), Redis/Valkey, Mooncake, InfiniStore, S3-compatible object storage, NIXL, and GDS.
Non-prefix KV reuse: Extend KV reuse beyond prefix caching by reusing cached KV blocks at any position in the prompt. This leverages CacheBlend to selectively recompute tokens for quality recovery.
PD disaggregation and KV transfer: Support KV cache transfer from prefill workers to decode workers over NVLink, RDMA, or TCP through transport layers such as NIXL.
Pluggable KV transformation: A simple interface for researchers to write compression, token dropping, and custom serialization through a flexible SERDE interface.
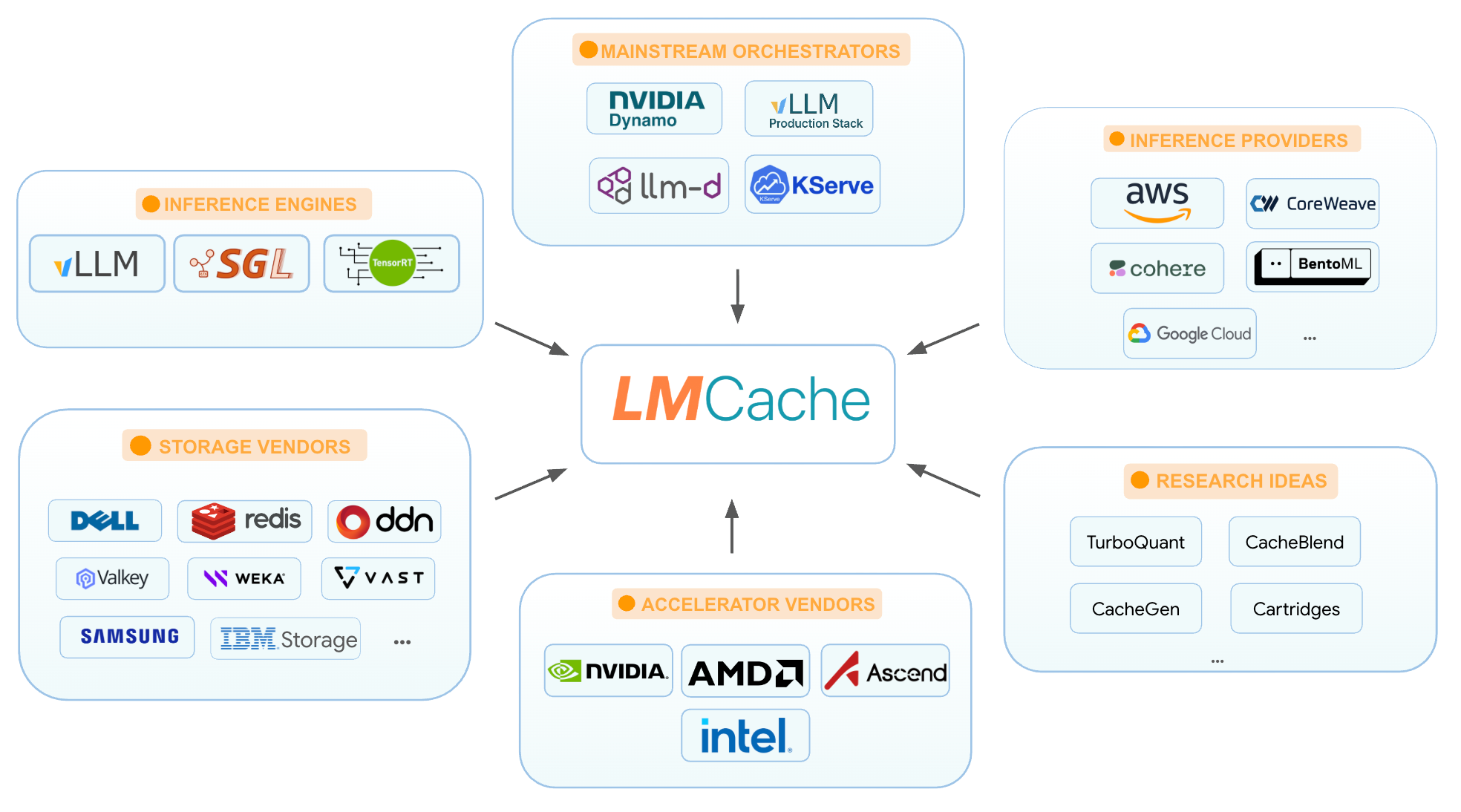
LMCache is becoming an integral layer in the LLM inference ecosystem, with community-driven integration with serving engines, inference frameworks, hardware vendors, storage systems, and infrastructure providers:
Updates#
[2026/06] 🔥 LMCache multi-platform development support with no GPU required (blog, blog).
[2026/05] 🔥 Agentic workload benchmark on AMD MI300X (blog).
[2026/04] 🔥 LMCache’s new multiprocess (MP) architecture release (blog).
[2026/03] LMCache at GTC 2026 (post).
[2026/01] LMCache multi-node P2P CPU memory sharing, from experimental feature to production (blog).
More
[2025/11] LMCache x CoreWeave accelerate efficient LLM inference for Cohere (blog).
[2025/10] LMCache joins the PyTorch Foundation and Tensormesh unveiled (blog, PyTorch).
[2025/09] NVIDIA Dynamo integrates LMCache, accelerating LLM inference (blog).
[2025/08] 🎉 LMCache hits 5,000+ GitHub stars (blog).
[2025/08] LMCache supports gpt-oss (20B/120B) on day 1 (blog).
[2025/07] Get faster LLM inference and cheaper responses with LMCache and Redis (Redis blog).
[2025/07] LMCache extends its turbo-boost to multimodal models in vLLM V1 (blog).
[2025/06] LLM Production Stack goes cross-hardware: AMD, Arm and Ascend (blog).
For more information, check out the following:
Our papers: