Mooncake#
警告
本页面记录了 LMCache 的进程内模式(已弃用)的行为。请考虑使用 LMCache MP 模式 以获得更好的功能支持和性能。有关此页面的 MP 模式等效内容,请参见 Mooncake Store。
概述#
Mooncake 是一个开源的分布式 KV Cache 存储系统,专为 LLM 推理场景而设计。该系统通过聚合多个客户端节点贡献的内存空间,创建一个分布式内存池,从而实现跨集群的高效资源利用。
通过整合多个节点下的未充分利用的 DRAM 和 SSD 资源,该系统形成了一个统一的分布式存储服务,最大化资源效率。
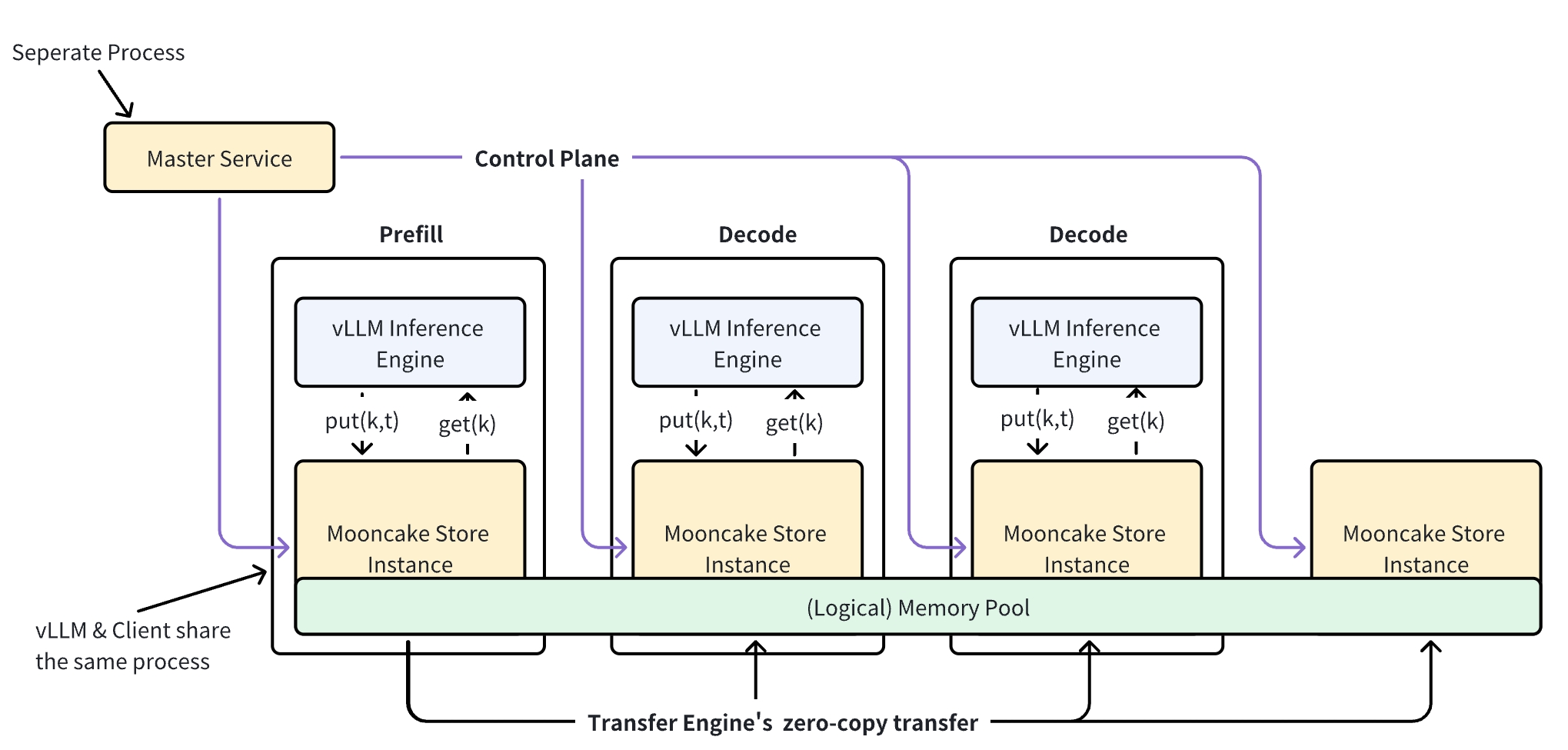
关键特性#
分布式内存池:将多个客户端节点的内存贡献聚合到一个统一的存储池中
高带宽利用率:支持大对象的条带化和并行 I/O 传输,充分利用多 NIC 聚合带宽
RDMA 优化:基于传输引擎构建,支持 TCP、RDMA(InfiniBand/RoCEv2/eRDMA/NVIDIA GPUDirect)
动态资源扩展:支持动态添加和移除节点以实现弹性资源管理
有关详细的架构信息,请参阅 Mooncake Architecture Guide。
快速开始#
通过 pip 安装 Mooncake:
pip install mooncake-transfer-engine
此软件包包含所有必要的组件:
mooncake_master:管理集群元数据并协调分布式存储操作的主服务mooncake_http_metadata_server: 基于 HTTP 的元数据服务器,用于底层传输引擎的连接建立Mooncake Python 绑定
对于生产部署或自定义构建,请参阅 构建说明。
设置和部署#
前提条件:
具有至少一个 GPU 的机器用于 vLLM 推理
支持 RDMA 的网络硬件和驱动程序(推荐)或 TCP 网络
Python 3.8+ 和 pip
已安装 vLLM 和 LMCache
步骤 1:启动基础设施服务
启动 Mooncake 主服务(带内置 HTTP 元数据服务器):
# Master service (use -v=1 for verbose logging)
# The flag enables the integrated HTTP metadata server
mooncake_master --enable_http_metadata_server=1
预期输出:
Master service started on port 50051
HTTP metrics server started on port 9003
Master Metrics: Storage: 0.00 B / 0.00 B | Keys: 0 | ...
步骤 2:创建配置文件
创建您的 mooncake-config.yaml:
# LMCache Configuration
local_cpu: False
remote_url: "mooncakestore://localhost:50051/"
max_local_cpu_size: 2 # small local buffer
numa_mode: "auto" # reduce tail latency with multi-NUMA/multi-NIC
pre_caching_hash_algorithm: sha256_cbor_64bit
# Mooncake Configuration (via extra_config)
extra_config:
use_exists_sync: true
save_chunk_meta: False # Enable chunk metadata optimization
local_hostname: "localhost"
metadata_server: "http://localhost:8080/metadata"
protocol: "rdma"
device_name: "" # leave empty; autodetect device(s)
global_segment_size: 21474836480 # 20 GiB per worker
master_server_address: "localhost:50051"
local_buffer_size: 0 # rely on LMCache local_cpu as the buffer
mooncake_prefer_local_alloc: true # prefer local segment if available
步骤 3:使用 Mooncake 启动 vLLM
# If you see persistent misses (no Mooncake hits), make sure
# PYTHONHASHSEED is fixed across processes (e.g., export PYTHONHASHSEED=0).
LMCACHE_CONFIG_FILE="mooncake-config.yaml" \
vllm serve \
meta-llama/Llama-3.1-8B-Instruct \
--max-model-len 65536 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
步骤 4:验证设置
使用示例请求测试集成:
curl -X POST "http://localhost:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3.1-8B-Instruct",
"prompt": "The future of AI is",
"max_tokens": 100,
"temperature": 0.7
}'
调试提示:
启用详细日志记录:
mooncake_master -v=1检查服务状态:
# Check if services are running ps aux | grep mooncake netstat -tlnp | grep -E "(8080|50051)"监控指标:
当主服务运行时,可以在
http://localhost:9003访问指标。
配置#
LMCache 参数:
参数 |
默认 |
描述 |
|---|---|---|
|
256 |
每个 KV 块的令牌数量 |
|
必需的 |
Mooncake 存储连接 URL(格式: |
|
“简单” |
远程存储的序列化方法 |
|
假 |
启用/禁用本地 CPU 缓存(设置为 False 以进行纯 Mooncake 评估) |
|
必需的 |
本地 CPU 缓存的最大大小(以 GB 为单位)(即使 local_cpu 为 False 也需要) |
|
自动 |
NUMA 绑定模式。在多 NIC/多 NUMA 系统上,推荐使用 "auto" 以减少尾部延迟。 |
|
sha256_cbor_64bit |
用于预缓存键的哈希。为了跨进程的一致性,固定 |
Mooncake 参数(通过 extra_config):
参数 |
默认 |
描述 |
|---|---|---|
|
必需的 |
Mooncake 客户端识别的本地节点的主机名/IP |
|
必需的 |
HTTP 元数据服务器地址。当使用 |
|
必需的 |
Mooncake 主服务地址(主机:端口格式) |
|
rdma |
通信协议(“rdma”用于高性能;“tcp”用于兼容性) |
|
"" |
RDMA 设备规格(例如,"erdma_0,erdma_1" 或 "mlx5_0,mlx5_1")。在大多数设置中留空以进行自动检测。 |
|
21474836480 |
每个 vLLM 工作线程贡献的内存大小(以字节为单位,例如,推荐 20 GiB) |
|
0 |
Mooncake 使用的本地缓冲区大小(以字节为单位)。行为取决于 |
|
1 |
传输操作的超时时间(以秒为单位) |
|
"" |
持久化的根目录(例如,"/mnt/mooncake") |
|
假 |
是否在数据旁边保存块元数据。设置为 |
|
假 |
使用同步存在性检查以避免热路径中的异步调度开销。 |
|
假 |
在可能的情况下,优先在本地段上分配。 |
重要
理解 global_segment_size:该参数定义了每个 vLLM 工作线程为分布式内存池贡献的内存量。KV Cache 存储可用的总集群内存将为:number_of_vllm_workers × global_segment_size。
根据您的可用系统内存和预期的缓存需求调整此值。
小技巧
如果您持续遇到未命中(没有 Mooncake 命中),请确保所有进程使用相同的哈希种子:export PYTHONHASHSEED=0。这可以保持跨进程的预缓存键一致。
备注
RDMA 设备通常不需要指定;将 device_name 留空适用于大多数部署。