Maru#
警告
本页记录了 LMCache 的进程内模式(已弃用)的行为。请考虑使用 LMCache MP 模式 以获得更好的功能支持和性能。有关此页面的 MP 模式等效内容,请参见 二级 KV 存储。
概述#
Maru 是一个高性能的 KV Cache 存储引擎,基于 CXL 共享内存构建,旨在用于 LLM 推理场景,在这些场景中,多个实例需要以最小延迟共享 KV Cache。
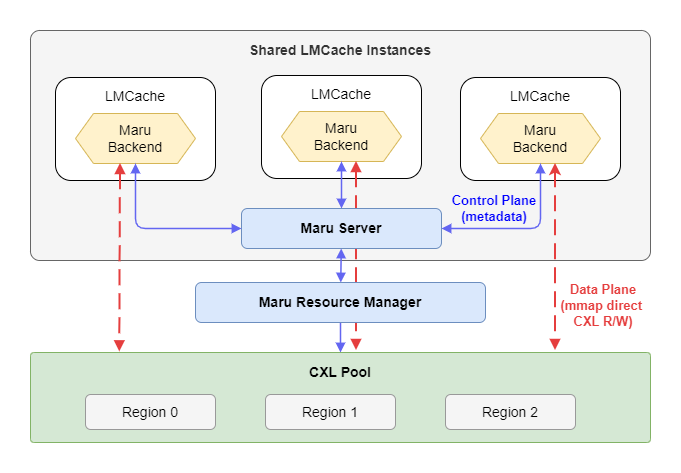
有关架构的详细信息,请参阅 Maru 文档。
快速开始#
安装 Maru:
git clone https://github.com/xcena-dev/maru.git
cd maru
./install.sh
这将安装 maru-server、maru-resourced 和 maru Python 包。
使用 Maru 部署模型#
前提条件: CXL 设备(/dev/dax*),安装 Python 3.12+、vLLM 和 LMCache。
1. 启动 Maru 服务器
maru-server
2. 创建配置文件 (maru-config.yaml):
chunk_size: 256
local_cpu: False
max_local_cpu_size: 0
save_unfull_chunk: True
# Maru backend
maru_path: "maru://localhost:5555"
maru_pool_size: 4
3. 使用 Maru 启动 vLLM
LMCACHE_CONFIG_FILE="maru-config.yaml" \
vllm serve \
meta-llama/Llama-3.1-8B-Instruct \
--max-model-len 65536 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
配置#
LMCache 参数:
参数 |
默认 |
描述 |
|---|---|---|
|
必需的 |
Maru 服务器 URL(格式: |
|
|
每个实例的 CXL 内存池大小(单位:GB,例如 |
高级参数(通过 extra_config):
参数 |
默认 |
描述 |
|---|---|---|
|
自动 UUID |
唯一客户端实例标识符 |
|
5000 |
ZMQ RPC 套接字超时(毫秒) |
|
真 |
异步 DEALER-ROUTER RPC ( |
|
64 |
最大并发异步 RPC 请求数 |
|
真 |
在连接时预先映射所有共享区域 |